Happy hacking: 给Gnome Shell的音量菜单加上设备选择
从亲戚那里得到了一对USB小音箱,正好弥补本本的声音太小的不足。本本的音量接口长年接着耳机,怕打扰到别人的时候用耳机,平时开音箱。
然而切换耳机和音箱太麻烦了。USB音箱的本质是一块USB声卡,要在这两个设备之间切换,就是在内置声卡和USB声卡之间切换。在Gnome Shell下,最快的切换路径应该是右上角的音量指示器->声音设置->输出->选择输出设备。对于要经常切换的人来说每次都要执行这么大一步是很痛苦的。稍微好一点的方案就是打开声音设置后不关闭,每次要切换就切换到声音设置窗口,然后直接切换设置。但是……有谁愿意整天开着个基本没用的窗口呢?
于是在重复了数十次这样的操作后,我终于受不了了。为什么不直接在音量菜单上加上设备切换的功能呢?我决定把Gnome Shell的音量指示器给hack一下,满足我的需求。
Gnome的音量指示器代码在/usr/share/gnome-shell/js/ui/status/volume.js文件里,主要用到一个叫Gvc的组件,这个组件没有文档,只好看gnome shell里的代码。研究了一晚上,基本实现了我的需求:当设备小于2个时,和系统自带的音量菜单没有区别;当设备大于等于2个时,在音量条下方会显示所有的设备,单击即可切换。如下图所示:
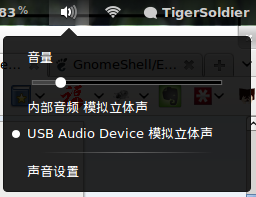
我把改动做成了扩展的形式,启用后会替代原有的音量指示器给原来的音量菜单加上输出设备切换项,禁用后还原。扩展已经提交到Gnome Shell Extension网站上了,地址是https://extensions.gnome.org/extension/142/output-device-chooser-on-volume-menu/,目前还在审核中已经通过审核。
代码依旧托管在github上,地址为https://github.com/tigersoldier/Output-device-chooser-on-volume-menu
PS:在研究代码时发现可以直接用滚轮在音量图标上调整音量大小,不必打开音量菜单。@csslayer表示KDE一直有这个功能,我用gnome2的时候一直没试过,不知道gnome2和ubuntu的sound indicator是不是也有这么贴心的设计。
ibus的GNOME Shell扩展
Update:
- 更新代码,支持横排模式(设置后需要重启gnome shell)
- 这个扩展使用了ibus的一些新API,该API还没有发布,需要自行编译ibus的git仓库代码
以前说过GNOME3的一个缺点,在通知栏聊天时,无法看到ibus的候选词界面,确切地说是候选词界面被通知栏聊天界面挡住了。这是GNOME Shell的架构所决定的,目前没有方法可以绕过(除非修改GNOME Shell)本身。唯一的解决方法就是将ibus的界面用GNOME Shell的那一套(Shell Toolkit, St)实现。
当GtkWindow绘制背景遇上Resize
缘起
在实现OSD Lyrics的滚动模式的时候,我发现在拖动改变窗口大小时,窗口内容会变得支离破碎。进一步实验发现,只要是直接在窗口上绘图,必然会导致这个结果。例如下面的python代码:
GTK 2.20 中的input shape mask问题
在OSD Lyrics中,我使用以下代码,来实现鼠标穿透功能:
1 2 3 4 5 6 7 8 9 10 | gdk_drawable_get_size (osd->osd_window, &w, &h);GdkPixmap *input_mask = gdk_pixmap_new (NULL, w, h, 1);GdkGC *gc = gdk_gc_new (input_mask);GdkColor color;color.pixel = 0; /* black */gdk_gc_set_foreground (gc, &color);gdk_draw_rectangle (input_mask, gc, TRUE, 0, 0, w, h);gdk_window_input_shape_combine_mask (osd->osd_window, input_mask, 0, 0);g_object_unref (input_mask);g_object_unref (gc); |
简单来说,就是生成一个w*h的黑白pixmap,用绘制矩形的方法将它的所有像素置零,然后将它作为OSD窗口的input shape mask,使得在其上的所有鼠标事件都不会被OSD窗口捕捉。
这段代码在之前一直工作很正常,但是最近有人报告说穿透功能失效了。然而这项功能在我的Ubuntu 9.10上很正常,于是我怀疑是与Gnome 2.30自带的GTK 2.20有兼容性问题。
最近把系统升级到了10.04,GTK升级到了 2.20,果然问题出现了。无论color的pixel设为0还是1,都没法产生效果。进一步实验发现,如果去掉gdk_draw_rectangle一句,也就是生成pixmap后不绘制任何东西,那么input mask是可以生效的。一旦在上面绘制矩形,不论怎么绘制,绘制的部分都会没有穿透效果,也就是说,被绘制的部分成了有遮挡的标记。
但是不能直接把绘制矩形的部分去掉,因为在低版本的GTK中,gdk_pixmap_new返回的pixmap并不是所有像素都置零的,也就是mask是一个随机的效果,这也是为什么我在实现的时候要画个矩形。一个比较丑陋的解决方法就是判断GTK的版本,如果版本小于2.20,就绘制矩形,否则不绘制。这个方法很恶心,而且天知道新的GTK出来后会不会出问题,至少在文档中没有对gdk_pixmap_new返回的pixmap作任何保证。
后来想到notify-osd在lucid下鼠标穿透的功能依然正常,查看了它的代码,发现对input_shape部分进行了大幅地修改,参考之后代码修改为如下形式:
1 2 3 | GdkRegion *region = gdk_region_new ();gdk_window_input_shape_combine_region (osd->osd_window, region, 0, 0);gdk_region_destroy (region); |
就是创建一个空区域,然后将它作为input shape,因为是空区域,所以整个OSD窗口都是镂空的。
虽然问题解决了,但是还是不明白,为什么之前的方法在GTK 2.20上不能用了(应该说是在GDK 2.20上不能用了),2.20在input shape mask和pixmap上有什么改动,上面的代码要作什么改动才能正常工作呢?如果有朋友知道,请告诉我:)
回归多进程下载模型
在用多进程下载模型可耻地失败之后,OSD Lyrics使用了多线程模型来对歌词进行下载。在完成之后发现每当DNS超时时,程序都会崩溃。经过不断地调试,确定是curl的问题。看了文档后发现,原来curl在多线程环境下,由于DNS查找超时是使用信号实现的,所以在多线程环境下是不安全的。当时想了两个方法:在自己的程序里包含curl,启用异步DNS查询cares;或者大幅修改程序,使用curl的异步查询接口重写下载引擎,把程序重新变成一个单进程、单进程的程序。第一种方法会让代码的大小和编译时间大幅增长,第二种方法要把两个下载引擎(搜狗和千千的)给大幅改写,过于复杂。于是一直纠结……
后来请教了 @henry_ 老师,一句话把我打回原点——用多进程才是王道。
进程vs线程
重新审视自己的设计和多进程模型失败的原因:因为在子进程中使用了X的操作。为什么会有X的操作呢?看看下载一个歌词的步骤:
- 搜索歌词,并将搜索结果返回
- 如果有多个搜索结果,弹出选择窗口
- 下载选中的歌词
- 下载成功,显示歌词
之所以会有X操作,是因为第2步弹出了一个窗口。由于子线程同样不能操作GUI元素,因此多线程模型同样要在主线程中处理弹出窗口。我在设计中将下载过程给模块化了,有一个专门的下载模块,将具体的下载引擎和主程序分开。线程化后的下载过程是这样的:
- 主程序向下载模块注册搜索和下载回调函数
- 主程序发起搜索请求
- 下载模块建立搜索线程,搜索线程调用下载引擎的搜索函数,返回后唤醒下载模块在主线程的回调函数
- 下载模块的回调函数调用所有注册了的搜索回调函数
- 主程序的搜索回调函数弹出选择窗口
- 下载模块建立下载线程,下载线程调用下载引擎的下载函数,返回后唤醒下载模块在主线程的回调函数
- 下载模块的回调函数调用所有注册了的下载回调函数
- 主线程的下载回调函数显示歌词
也就是说,只是将原来的第1步和第3步线程化了,而这两步是没有X操作的。而且由于将下载过程都放在下载模块里了,因此多线程部分完全是在下载模块里实现的,主程序和下载引擎一点也不知道多线程的存在。
既然如此,为何不讲它们进程化呢?把实现中的线程改成进程,就是多进程模型了。一旦这样做的话:
- 子进程中没有X操作
- 只需要修改下载模块,主程序和下载引擎不需要修改,工作量小,不易出错
- 多进程不会再有信号的问题。更进一步来说,子进程你爱挂就挂吧,对父进程半点影响都没有,多健壮啊
- 进程之间没有公共数据,无需同步,不怕数据修改
- 我管你子进程怎么分配内存,反正一退出全回收了
- ……………………
明白自己要什么
首先搞清楚自己需要怎样的多进程操作:
- Unix的
fork风格 - 异步函数调用形式,在fork时指定回调函数,子进程退出后自动调用回调函数
- 子进程能返回数据到回调函数中,不只是退出状态
简单来说,就是要一个刚好能替代现有线程操作的方案,而且它是和现在的线程操作类似的,这样使用起来直观,而且修改难度小。
然而我遇到了一个问题。
如何从子进程中返回数据
从子进程中返回数据的问题思考了很久,因为进程间通信不像线程间通信那么简单,直接传一个指针完事。@henry_ 老师给我指明了两条路:使用管道或共享内存。
就此思考了一番。管道需要将返回数据序列化,再通过管道传送,最后反序列化还原数据。共享内存不需要序列化,但是需要自己管理内存,而且不知道要开多大的共享内存,内存的分配与释放都要仔细考虑。
最后的决定是使用管道。虽然要实现序列化操作,但是过程简单清晰。如果使用共享内存,那么设计会变得很复杂,容易出错,而且内存相互分离的优点也没了。
具体设计
把一切都想清楚之后设计就很清晰了。
- fork前打开管道
- fork时指定回调函数
- 子进程使用管道写入数据,然后退出
- 父进程从管道读入数据,然后调用回调函数并将数据传入
- fork模块只负责传递数据,不负责序列化操作
最后的设计只有一个函数:
1 | pid_t ol_fork (OlForkCallback callback, void *userdata); |
回调函数的定义如下:
1 2 3 4 | typedef void (*OlForkCallback) (void *ret_data, size_t ret_size, int status, void *userdata); |
同时,为子进程提供了用于返回数据的文件描述符和文件流:
1 2 | extern int ret_fd;extern FILE *fret; |
实现细节
剩下的最大问题就是如何在子进程退出时调用回调函数了。最直接的想法就是处理SIGCHLD信号。由于不同的子进程可能需要调用不同的回调函数,也有不同的用户数据,因此需要有一个子进程ID和回调函数的对应表。感谢GTK、GDK、GLib,现在只需要用g_child_watch_add就一切都搞定了。
关于序列化,本来是想用protobuf的,它的C绑定似乎还直接提供了RPC的支持。由于我只是简单的需要一个IPC的数据传递,干脆自己写一个来练手好了。
序列化的协议很简单。因为只有两种结构需要序列化——数组和结构体,所以就简单地定义了一下。对于结构体,将其字段按一定顺序输出,以换行符间隔。对于数组,先输出一行总数,再输出各元素,每个元素后再加上一个换行符。由于是程序内部用的IPC数据,因此只要单元测试通过了,数据的正确性就可以完全信赖,不需要复杂的容错机制。
一些弯路
一开始在考虑子进程返回的触发时,@henry_ 提示可以用select或者poll。实现了之后发现有两个问题,一是如果子进程的返回数据是分段输出的话,回调函数可能会调用几次,每次收到一段数据;二是如果子进程没有返回数据(也就是返回数据为空),那么回调函数根本就不会运行。因此还是老老实实采用子进程退出来触发回调函数。
开始的设计是向回调函数传递一个fd,让回调函数自己读取数据。这么做是为了能让回调函数利用fgets来读取一行。思考之后觉得这样很不自然,而且回调函数要考虑的东西反而多了,复杂了,于是改成了现在这个样子。
在实现序列化的时候没有想清楚,把不需要序列化的OlMusicInfo给序列化了,白做工了。
在反序列化结构时,一开始是返回true or false,后来发现一个问题,就是在反序列化数组时,不知道一个元素反序列化后,剩下未被反序列化的数据从哪开始。于是把接口改成了返回指向剩下数据开头的指针,如果失败就返回NULL。
结论
把fork模块和序列化做好之后,修改代码就很简单了,只需要把对应的地方改一下,程序很欢快地跑了起来。
使用多进程的设计,避免了修改curl使用方式的缺点,而且使得程序更健壮。由于Linux轻量级进程的优势,多进程和多线程的性能应该没有太大的差别,而且实际上下载也不是程序的瓶颈。
此次设计进行了仔细考虑,而没有像之前边做边迭代的方法。在明确自己的目标,排除多余的东西,对各方面作出权衡和折衷之后,得到了一个比较简洁的接口和实现,自己觉得还是很满意的。
实现的过程中对新的代码做了充足的单元测试,发现了一些问题,同时修正了设计,最后用起来自己也相当放心。在代码不是立刻可以整合到系统中的时候,单元测试往往是能立刻看到成果的方式,而且也能检验自己的设计是否合理。
从多进程到多线程,最后又回到多进程,貌似绕了个大弯又回到原点。但是这两个多进程的设计高度完全不一样。在实现了多线程机制后,对整个下载的过程和实现有了充分的了解,现在的多进程流程也是在多线程的设计中定下的。如果没有多线程模型这个探索,也就很难有现在这个设计。所谓螺旋式上升嘛,说不定以后又会改成多线程,但是可以肯定的一点是,一定会比现在的要更好。
一个类型提升引发的bug
今天OSD Lyrics收到了一个issue,说是在歌手不存在的情况下xmms2搜索歌词成功,下载歌词失败。之前在Exaile下也有类似的bug,不过这个bug的问题不同(应该说Exaile下也还是会有这个问题)。
OSD Lyrics对歌词文件名的查找是基于模板的,模板中有一些占位符,例如%t代表歌名,%p代表歌手。有一个函数ol_path_get_lrc_pathname,负责给定路径模板和文件名模板以及歌曲信息,输出根据模板转换后的完整文件路径。成功时返回输出的路径长度,失败则返回-1。
但是在程序日志中发现,当歌手为空时,文件名模板“%p-%t”应该是失败的,然而却依然被当作成功来使用。这样一来,匹配的结果就成了只有目录,缺少文件名的路径,把歌词下载的目标地址设成本机的一个目录,那肯定是会失败的嘛。
把ol_path_get_lrc_pathname相关的函数里外查了一遍,没有任何问题,出错时也的确返回了-1,于是目光落到调用这个函数的地方:
1 2 3 4 5 6 | if ((ol_path_get_lrc_pathname ( path_list[i], name_list[j], info, file_name, MAX_PATH_LEN)) >= 0){ /* do something */} |
发现把>=0改成!=-1就正常了。
为什么会这样?原因就在于ol_path_get_lrc_pathname的返回类型是size_t,而size_t在我的系统里的定义是unsigned int。任意一个unsigned类型都不会小于0。
那么为什么改成!=-1后,反而又可以了呢?任意一个unsigned类似应该都不会等于-1呀。
这就涉及到C语言的类型提升问题了。在C语言中,那个操作数的类型不同时,会把操作数都转化成两个操作数中能表示的范围最大的类型。就表示的类型来说,shot<=int<=long<float<double,这个是没有任何问题的。问题在于,当出现了unsigned后,怎样计算。具体来说,两个操作数是unsigned int 和 int时,如何转化?
如果是unsigned short int和short int就好办了,直接转成int就行。然而很可惜,在32位机子里,int = long,把unsigned int和int转成long不能解决任何问题。
怎么办呢?很简单,两个都转成unsigned int。
在这个例子中,两个规则是一样的,因为返回的-1变成了size_t后,变成了最大的unsigned long,所以-1也跟着被转成了unsigned long,变成了0xFFFFFFFF,两个刚好又相等了:)
作为一个例子,请看下面一段代码:
1 2 3 4 5 6 7 8 9 | #include <stdio.h>int main(){ unsigned long a = 0; long b = -1; printf ("%s\n", a > b ? "Greater" : "Less"); return 0;} |
会输出什么呢?gcc 4.4.1给出的答案是Less,因为-1被转型了:(
多进程下载歌词尝试失败
OSD Lyrics的一个最大的问题就是它的单进程单线程模型,这使得它在搜索和下载歌词的时候会阻塞正常的歌词显示,导致在下载未完成时切换歌曲会出现无响应的情况。
由于基础太弱,这个问题一直被我搁着,直到把APUE的前17章都看了一遍,对Unix系统下多进程/线程有了大概的了解,终于开始着手改造下载模块了。为了不影响主分支的开发,我在之前就已经创建了一个branch用于尝试异步下载的实现。
本着KISS的原则,第一个想法非常简单:
- 在准备下载时,fork出一个进程,父进程直接返回,子进程继续执行下载任务
- 子进程下载后直接中止进程
- 父进程在收到SIGCHLD信号后检查当前正在播放的音乐的歌词是否已被下载
这个想法,如果不涉及GUI,是可以很好地工作的,但是一旦要显示一个GUI让人选择要下载的歌词,就直接崩溃了。看来X相关的东西不能直接fork来多弄出一份,不过这也是很自然的。
看来之前建了一个branch是明智的,这个要折腾的时间确实比较长。
于是接下来似乎只有两条路可以走了:
- 用glib来创建一个线程,再想办法在搜索和下载成功时向主线程的消息循环插入一条消息
- 研究curl相关的异步下载方法
又要开始看文档鸟>_<
GNU hello学习笔记(1)——autoconf和automake
什么是 GNU hello
GNU hello 是 GNU 推出的 hello world 软件,就是将入门的 hello world,以正规的 GNU 规范来实现,从而来展示 Unix-like 系统下开发软件的一些常用技术和软件的组织方法。麻雀虽小,五脏俱全,GNU hello 虽然只是一个 hello world,却包含了如下几项技术:
- Automake 和 Autoconf:生成编译配置脚本
- Gnulib:程序的基本函数库
- Gettext:国际化支持
- getopt:命令行参数支持
- help2man:用程序的--help选项输出生成manpage
- Texinfo:编写程序文档
如何学习 GNU hello
最好的方式莫过于自己参照 GNU hello 弄个自己的 hello world 出来,把其中的各项有用技术都自己玩个遍。只看书永远没有实践来得实在,不是么?
程序主要的新东西自己手写,一些体力劳动就直接复制粘贴了。最终出来的内容不一定与 GNU hello 完全相同。
本篇学习内容
基本的程序文件组织方式
- 基本的 Autoconf 和 Automake 配置文件写法及其原理
好了,现在开始!
程序文件的组织
严格来说,一个程序并没有什么标准的组织规范,任何组织形式都是可以的。但是良好的程序文件组织结构可以让人快速定位开发文件,更好地管理项目。在长期的实践中,Unix社区对一些常见文件的组织逐渐形成了一些传统,这些传统不仅是经受了时间的考验,也能让别人更好的了解自己的项目文件组织结构。
在 GNU hello 中,文件是这样组织的(设“/”是代码根目录)
- \:根目录存放automake和autoconf等配置文件,以及程序的一些说明文件(NEWS、Changelg、COPYING、INSTALL、AUTHORS等)
- build-aux:automake 和 autoconf 自动生成的一些脚本
- contrib:暂时不明
- doc:程序文档
- gnulib:Gnulib 的各文件
- man:manpage存放地
- po:gettext 翻译文件
- src:程序源文件
- tests:测试脚本
在其他项目中,我见过的有doc、man、po和src,这些应该是约定俗成的命名。另外会生成库文件的项目不少是把库文件放在lib目录下的。
Autoconf 和 Automake
它们是干啥的?
Unix下的软件,编译安装一般来说是要运行如下三条命令:
1 2 3 | ./configuremakemake install |
make是通过Makefile里指定的命令与目标来进行相应操作的程序,可以简单地理解为一串指令的集合(当然, 它远远不止于此)。用它就不必为编译代码写一条条的指令,只要把相关的指令写在Makefile里,直接make就行了。
然而不同的系统里装的软件不一样。可能一台机子里装了gcc,另一台机子里装的是cc。为了使Makefile能在所有机子里通用,就了有configure脚本。代码里并不带有Makefile,只有一个模板文件Makefile.in,里面用变量来定义要使用的命令,由configure脚本将检测到的工具填入Makefile.in生成Makefile。
但是不论是configure脚本还是Makefile,都并不是两句话可以写完的,而其内容多是类似的重复内容,于是就有了autoconf和automake。它们通过一些相对简单的语法来生成标准的configure脚本和Makefile。
准备工作
写一个最简单的hello world,存为src/hello.c:
1 2 3 4 5 6 7 8 | #include <stdio.h>intmain (int argc, char *argv[]){ printf ("hello world!"); return 0;} |
编写configure.ac
configure.ac是autoconf的配置文件,可以通过autoscan来辅助生成。旧版本的autoconf使用configure.in,现在这两个文件名都是通用的
在顶层目录运行autoscan,软件自动生成configure.scan,这是一个根据现有代码生成的configure.ac模板,将它另存为如下的configure.ac文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # 初始化autoconf,这句必须写在其他之前。定义的参数分别为软件名,版本号,维护地址(网站/邮件)AC_INIT([TS Hello], [0.1], [tigersoldi<at>gmail<dot>com])# [可选]定义生成的辅助文件的目录,默认是与configure.ac同目录AC_CONFIG_AUX_DIR([build-aux])# 初始化automakeAM_INIT_AUTOMAKE([readme-alpha])# 定义需要的autoconf最低版本,这是autoscan自动生成的,未必需要这么高的版本AC_PREREQ([2.63])# 定义源代码的路径,通过指定源代码目录内一个存在的文件来指定AC_CONFIG_SRCDIR([src/hello.c])# 检测C编译器AC_PROG_CC# 生成配置文件,配置文件都是将`配置文件.in'进行变量替换后得到的AC_CONFIG_FILES([Makefile src/Makefile])# 生成上面要求输出的文件AC_OUTPUT |
编写Makefile.am
与autoconf类似,automake的配置文件是Makefile.am,它会用此来生成Makefile.in文件,该文件是configure脚本用来生成Makefile文件的模板。
与configure.ac不同,我们要为每个文件夹写一个Makefile.am文件
根目录下的Makefile.am文件很简单,它不用做任何事情, 只要告诉make它有个子目录src,让make去操作src目录:
1 2 | #处理如下子文件夹SUBDIRS = src |
src目录下的Makefile.am指定了我们要编译的程序及其文件:
1 2 3 4 5 | # 定义要编译的程序hello,可以有多个,用空白符(空格、TAB、行末加了`\'的换行)分开bin_PROGRAMS = hello# 定义hello的源文件,必须以`<程序名>_SOURCES'的形式来定义,# <程序名>就是bin_PROGRAMS中定义的程序之一,同样可以有多个源程序hello_SOURCES = hello.c |
编译程序
文件都准备好后,就可以开始编译了。在编译之前,我们先让autoconf和automake生成我们需要的文件(确保在程序根目录):
1 2 3 4 5 6 7 8 9 10 | # 将configure.ac里所需要的M4宏复制到文件夹中aclocal# 通过configure.ac生成configure脚本autoconf# 创建build-aux文件夹mkdir build-aux# 创建GNU要求的说明文件touch NEWS README AUTHORS ChangeLog # 通过Makefile.am生成Makefile.in模板automake --add-missing --copy |
其中,aclocal是为autoconf进行准备工作的。
automake默认是GNU模式,GNU规范要求程序包含(NEWS README AUTHORS ChangeLog)等说明文件,我们用touch暂创建几个临时文件上去。
automake还需要创建一些辅助脚本,这些脚本由--add-missing选项添加到目录中。由于在configure.ac里用AC_CONFIG_AUX_DIR定义到了build-aux目录下,我们要先创建这个目录。如果没有指定--copy,那么创建的是指向automake安装目录相应文件的符号链接,指定后是直接复制一份。
可以看到autoconf创建了configure脚本,而automake则在程序根目录和src子目录下创建了Makefile.in,接下来就用configure脚本配合Makefile.in来生成Makefile:
1 | ./configure |
由于我们在configure.ac里用AC_CONFIG_FILES指定了生成Makefile和src/Makefile两个文件,configure脚本通过相应的.in文件替换到检测到的相应变量后生成。注意生成的文件不仅限于Makefile,任何文件名都是可以的,只要它有.in模板。
有了Makefile就可以make啦:
1 | make all |
直接用make也可以。all是指定的目标,也是一个约定俗成的目标(这是Makefile指定的,不同Makefile可以指定不同的目标,只要把它放在第一个就行),它的作用是编译程序。
于是现在可以执行Hello world了:
1 | ./src/hello |
可以看到我的hello world出现了:-)
换一个目标试试:
1 | make install |
install也是个约定俗成的目标,它把我们的软件安装到系统中。现在可以直接输入hello来运行软件了。
有安装自然也有卸载,卸载的目标是uninstall。
还可以用make clean来清除编译出来的文件。
GTK+ Widget的内部结构与工作流程
最近写了些GTK+的Widget,稍微了解了一下其内部结构,先记录下来,用以备忘。
GtkWidget的基本结构是这样的:
GtkStyle *GSEAL (style);
GtkRequisition GSEAL (requisition);
GtkAllocation GSEAL (allocation);
GdkWindow *GSEAL (window);
GtkWidget *GSEAL (parent);
} GtkWidget;
其中最重要的是它的window属性,每个GtkWidget都必须有一个window。Widget是围绕着window转的,只有有了window,Widget的存在才有意义。
要注意这里的window是一个GdkWindow,而不是GtkWindow。GdkWindow是对X的window的封装,大致上是屏幕上的一块矩形区域,可以在上面画画,可以接收事件。
一个Widget从创建、显示到销毁,大致要经过这么几个过程:
1、创建(new)
这是调用gtk_xxx_new时所触发的。它干的活很简单,用gobject的对象系统创建一个相应widget的实例。
当创建实例时,gobject会自动调用指定的初始化(init)函数(在get_type时指定),init函数负责把widget的各字段都初始化(把标题文字什么的设为NULL之类的)。
注意此时window并没有被创建,其实只是有了个widget的架子而已。
创建之后就可以对widget进行各种属性的设置了。
2、实例化(realize)
实例化的过程,就是将window创建出来的过程。这其中包括几个阶段:
- 询问大小请求(size_request):
GTK在实例化一个widget之前,会询问这个widget希望的大小是多大。widget可以根据自己的情况(例如属性什么的),计算出自己所需要的大小,也可以返回一个默认值,反正就是widget自己定啦:)。 - 分配大小(size_allocate):
GTK获得大小请求后就会给widget分配一个大小。要注意的是分配的大小不一定和请求的大小相同。一般来说,在分配大小时widget需要做几件事。
将分配的大小记录在自己的allocation中。
如果自己的window已经创建了,那么要改变自己所拥有的window的大小,使之符合所分配的大小。
如果widget是一个容器(container),那么对其所有的子widget也要相应地计算它们的大小并重新给它们分配大小。
分配大小可能发生在实例化之前,也可能在实例化后因为所属容器的大小、位置发生变化而被重新分配,因此widget的window可能已经被创建,也可能是NULL,需要进行判断。 - 实例化
这才是真正的实例化阶段。实例化所需要做的事只有一个:用gdk_window_new创建window。创建好window后需要用GTK_WIDGET_SET_FLAGS来给widget设置GTK_REALIZED标志。设置之后用GTK_REALIZED宏检查widget是否已经被实例化时会返回TRUE,表示该widget已经被实例化了。
可以用gtk_widget_realize手动实例化一个widget
3、映射(map)
所谓映射,就是将已经创建好的window映射(显示)到屏幕上。需要做的事是用gdk_window_show将window给显示出来。和实例化时类似,需要用GTK_WIDGET_SET_FLAGS设置GTK_MAPPED标志,表示已经映射好了。
要注意的是map时需要判断widget是否已经实例化(用GTK_REALIZED),如果没有,应该首先实例化widget,这样才能显示window。
同样可以用gtk_widget_map手动映射一个widget。
用gtk_widget_show来显示一个widget的本质,就是将widget实例化,并将其映射。当然每一步都要判断是否已经做过,重复实例化和映射会造成资源泄漏(window被多次创建)和其他问题。
以上就是一个widget从创建到显示的过程。当然其中还有其父widget的流程。一个widget当且仅当其父widget被实例化后才能实例化,映射亦然(放心,这个流程是GTK+自动判断的)
接下来就是销毁一个widget时要做的事了。
4、反映射(unmap)
当隐藏一个widget时,其实就是取消这个widget的映射。具体做法是用gtk_window_hide来隐藏window,并用GTK_WIDGET_UNSET_FLAGS来取消(GTK_MAPPED)。
5、反实例化(unrealize)
销毁一个widget之前会自动要求将其反实例化。反实例化就是将window给销毁(记得把window指针设回NULL),并取消(GTK_REALIZED)标志。
有时可能会需要用gtk_widget_unrealize来手动反实例化一个widget。
6、销毁(destroy)
和new对应,把剩下的资源释放,最后用gobject的相应函数释放整个widget
下面是取自GtkEntry中的典型代码:
创建:
gtk_entry_new (void)
{
/* 返回类型为GTK_TYPE_ENTRY的对象(Gobject的工作) */
return g_object_new (GTK_TYPE_ENTRY, NULL);
}
/* 初始化函数,在g_object_new时自动调用 */
static void
gtk_entry_init (GtkEntry *entry)
{
GtkEntryPrivate *priv = GTK_ENTRY_GET_PRIVATE (entry);
/* 设置widget标识 */
GTK_WIDGET_SET_FLAGS (entry, GTK_CAN_FOCUS);
/* 初始化各字段 */
entry->text_size = MIN_SIZE;
entry->text = g_malloc (entry->text_size);
entry->text[0] = '\0';
/* …… */
/* 设置拖放 */
gtk_drag_dest_set (GTK_WIDGET (entry),
GTK_DEST_DEFAULT_HIGHLIGHT,
NULL, 0,
GDK_ACTION_COPY | GDK_ACTION_MOVE);
gtk_drag_dest_add_text_targets (GTK_WIDGET (entry));
/* 输入法context */
entry->im_context = gtk_im_multicontext_new ();
/* 信号 */
g_signal_connect (entry->im_context, "commit",
G_CALLBACK (gtk_entry_commit_cb), entry);
/* …… */
}
大小分配:
gtk_entry_size_allocate (GtkWidget *widget,
GtkAllocation *allocation)
{
GtkEntry *entry = GTK_ENTRY (widget);
/* 保存到allocation中 */
widget->allocation = *allocation;
/* 判断是否实例化 */
if (GTK_WIDGET_REALIZED (widget))
{
/* 计算窗口大小…… */
/* 改变窗口大小 */
gdk_window_move_resize (widget->window, x, y, width, height);
/* …… */
}
}
大小请求:
gtk_entry_size_request (GtkWidget *widget,
GtkRequisition *requisition)
{
/* 计算所需大小…… */
/* 设置所城大小 */
if (entry->width_chars < 0)
requisition->width = MIN_ENTRY_WIDTH + xborder * 2 + inner_border.left + inner_border.right;
else
{
/* …… */
requisition->width = char_pixels * entry->width_chars + xborder * 2 + inner_border.left + inner_border.right;
}
requisition->height = PANGO_PIXELS (entry->ascent + entry->descent) + yborder * 2 + inner_border.top + inner_border.bottom;
/* …… */
}
实例化:
gtk_entry_realize (GtkWidget *widget)
{
/* …… */
/* 设置标志 */
GTK_WIDGET_SET_FLAGS (widget, GTK_REALIZED);
/* …… */
/* 创建window */
widget->window = gdk_window_new (gtk_widget_get_parent_window (widget), &attributes, attributes_mask);
gdk_window_set_user_data (widget->window, entry);
/* …… */
}
映射:
gtk_entry_map (GtkWidget *widget)
{
/* …… */
/* 判断是否可以且需要显示 */
if (GTK_WIDGET_REALIZED (widget) && !GTK_WIDGET_MAPPED (widget))
{
/* 调用父类的map函数,也就是GtkWidget的,这样就不用自己设置GTK_MAPPED和显示widget->window了 */
GTK_WIDGET_CLASS (gtk_entry_parent_class)->map (widget);
/* …… */
/* 显示需要显示的window */
gdk_window_show (icon_info->window);
/* …… */
}
反映射:
gtk_entry_unmap (GtkWidget *widget)
{
/* …… */
/* 判断是否需要隐藏 */
if (GTK_WIDGET_MAPPED (widget))
{
/* …… */
/* 隐藏需要显示的window */
gdk_window_hide (icon_info->window);
/* …… */
/* 调用父类的unmap函数,也就是GtkWidget的,这样就不用自己取消GTK_MAPPED和隐藏widget->window了 */
GTK_WIDGET_CLASS (gtk_entry_parent_class)->unmap (widget);
}
}
反实例化:
gtk_entry_unrealize (GtkWidget *widget)
{
/* …… */
/* 调用父类的unrealize函数来销毁widget->window和取消GTK_REALIZED标识 */
GTK_WIDGET_CLASS (gtk_entry_parent_class)->unrealize (widget);
/* …… */
}
销毁:
gtk_entry_destroy (GtkObject *object)
{
/* 销毁为成员分配的空间…… */
/* 用父类的object销毁函数自动调用gobject来销毁 */
GTK_OBJECT_CLASS (gtk_entry_parent_class)->destroy (object);
}
来宣布一下最近的项目
三月实习回来之后就有点手痒痒,和舍友sarlmolapple一起说想做个自由小项目,一则练习一下Linux下的编程,二则有点项目经验,三则可以自己用。敲定的项目是做桌面歌词,也就是在屏幕上显示的OSD歌词,我们规划了一下,基本应该具备的功能有:
- OSD歌词显示(这不是废话咩?)
- 歌词自动下载功能
- 支持多种播放器,也就是说,不是以一个插件的形式,而是以独立客户端的形式
项目用C来编写,基于GTK+。死党simplyzhao听了之后也很有兴趣,加入了进来。
其实现在已经有了挺不错的外挂歌词脚本lrcdis,为什么我们还要弄一个呢?其一是因为想自己做点东西,丰富经验,而做项目最大的动力就是自己要用。其二是因为lrcdis的OSD功能还很弱,而且由于是用bash脚本写的,应该很难增强(lrcdis是调用gnome-osd来实现OSD的)。
至于为什么用C,其实我觉得这个项目用Python来写会比较好,用C的唯一理由是……大家都想好好学学C-_-|||
其实这玩意计划了挺久了,现在原形设计得差不多了,技术问题也基本解决了,才敢公开出来。等到有可用代码的时候我会把项目地址给放出来的^ ^

![tigersoldi[at]gmail[dot]com](http://tigersoldier.is-programmer.com/user_files/tigersoldier/Image/gmail.png)