探索GObject(1):封装
Table of Contents
GObject?
C vs C++
C和面向对象,这不就是C++么?为什么要搞出另一套东西,而不直接使用C++呢?关于C与C++之争是一个大坑。Linux之父Linus就是力挺C而批判C++的。讨厌C++的人似乎认为C++过于复杂,内部机制陷阱过多等等。自己的经历不多,用C++也很少,达不到大牛们的境界,如果让我给个非要用C而不用C++的理由,我也给不出一个有说服力的。
为什么研究GObject
最原始的动力是,我在使用GTK+进行开发,而GObject是GTK+的基石。如果基础不牢,上层一定不会稳,因此很有必要把GObject给过一遍。知道了它的内部,才知道该如何使用它,明白它的机制与原理,做到心中有数。
但是研究GObject能带来更多。由于C里没有任何面向对象机制,因此GObject把这些机制全部实现了一遍。从中可以看到一些机制的实现原理,从而对面向对象有更多的理性了解。
第一步:封装
面向对象的最基本需求就是封装。所谓封装,按我的理解,就是将一系列相关数据,及对这些数据有关的操作,有序的组织在一个结构中。一个圆形有x坐标、y坐标、半径三个参数,我们可以用这三个变量表示一个圆:
1 | double x, y, radius; |
这没什么问题。现在多了一个圆,我们又要用三个变量:
1 | double x1, y1, radius1; |
当我们有很多个圆的时候,可能要用到数组:
1 | double x[100], y[100], radius[100]; |
问题在哪?x、y和radius是相互独立的。我完全可以定义100个x,200个y,150个radius。如果不只有圆,还有矩形,那么矩形的坐标叫什么呢?xx、yy?等你写了一堆代码之后回来看,到底x和y是圆的坐标,还是xx和yy是圆的坐标?
所以有了struct。一个struct对数据进行了很自然的封装:
1 2 3 | struct Circle { double x, y, radius;}; |
好了,现在我们有了Circle这个类型。这个类型将圆的三个参数封装到了一起,从现在开始它们就是一个整体了。我可以很自然的声明一个圆,而不是它的三个参数:
1 | struct Circle c; |
我们也不用担心x、y、z的数量不等了,更不用担心坐标和矩形坐标命名冲突——它们定义在Rectangle这个struct里呢:)。
事情还没有完。有了圆这个类型,那么对圆的操作呢?假设一个圆的操作之一为移动(move)。我们可以定义如下函数:
1 2 3 4 | void circle_move (struct Circle *self, double x, double y) { self->x = x; self->y = y;} |
我们输入一个圆的指针,以及新的x、y坐标,移动操作帮助我们把指定的圆移动到新的坐标上。注意第一个参数self,是不是有点眼熟?它就是C++里的this。记得学C++时很多同学对this理解相当困难,如果看这个self就不难理解了:self就是我们要操作的那个变量,它是一个指针。C++在对象方法调用时省略了这个参数,它可以被编译器自动设置。在C里面,这个工作要我们自己做。因此移动一个圆要这么调用:
1 2 | struct Circle cir;circle_move (&cir, 10.0, 5.0); |
注意self是个指针,因为C里没有引用,所以我们只能使用指针来达到传递一个对象,而不是传递它的复制品的效果。
这个方法……不就是普通的函数调用嘛,根本就没把操作给封装呀。好,现给一个看起来像C++中的方法:
1 2 3 4 5 6 7 8 | struct Circle { double x, y, radius; void (*move) (struct Circle *self, double x, double y);};...struct Circle cir;cir.move = circle_move;cir.move (&cir, 10.0, 5.0); |
通过函数指针,可以让move调用看起来更像C++了。但是,有两个不爽的地方。其一,要显式地将circlemove函数赋值给move函数指针,如果有5个圆,那就要5行指定的代码(除非用数组+循环)。更为严重的是我们可以为不同的变量指定不同move操作。其二,调用时依然要显示地指定self,这带来的一个后果是,我们完全可以调用cir1的move,但是传入的是cir2的指针。
对于第一点,可以使用类结构+初始化函数来解决。对于第二点,C语言是没法避免显示的传入self指针(如果可以的话请告诉我)。因此这种写法只是“像”C++而已,没啥实际的好处。不过在之后我们会看到,GObject会在类结构中使用函数指针来表示对象的操作。
小结
- 研究C下的面向对象实现,可以让我们更深入地了解面向对象的机理;
- 要将数据封装,可以使用struct;
- 要表示对某种对象的操作,定义一组函数,其第一个参数为要操作对象的指针。
话说,很有可能懒筋发作,然后这篇又留下一个坑-_-。希望不要如此吧……
GTK 2.20 中的input shape mask问题
在OSD Lyrics中,我使用以下代码,来实现鼠标穿透功能:
1 2 3 4 5 6 7 8 9 10 | gdk_drawable_get_size (osd->osd_window, &w, &h);GdkPixmap *input_mask = gdk_pixmap_new (NULL, w, h, 1);GdkGC *gc = gdk_gc_new (input_mask);GdkColor color;color.pixel = 0; /* black */gdk_gc_set_foreground (gc, &color);gdk_draw_rectangle (input_mask, gc, TRUE, 0, 0, w, h);gdk_window_input_shape_combine_mask (osd->osd_window, input_mask, 0, 0);g_object_unref (input_mask);g_object_unref (gc); |
简单来说,就是生成一个w*h的黑白pixmap,用绘制矩形的方法将它的所有像素置零,然后将它作为OSD窗口的input shape mask,使得在其上的所有鼠标事件都不会被OSD窗口捕捉。
这段代码在之前一直工作很正常,但是最近有人报告说穿透功能失效了。然而这项功能在我的Ubuntu 9.10上很正常,于是我怀疑是与Gnome 2.30自带的GTK 2.20有兼容性问题。
最近把系统升级到了10.04,GTK升级到了 2.20,果然问题出现了。无论color的pixel设为0还是1,都没法产生效果。进一步实验发现,如果去掉gdk_draw_rectangle一句,也就是生成pixmap后不绘制任何东西,那么input mask是可以生效的。一旦在上面绘制矩形,不论怎么绘制,绘制的部分都会没有穿透效果,也就是说,被绘制的部分成了有遮挡的标记。
但是不能直接把绘制矩形的部分去掉,因为在低版本的GTK中,gdk_pixmap_new返回的pixmap并不是所有像素都置零的,也就是mask是一个随机的效果,这也是为什么我在实现的时候要画个矩形。一个比较丑陋的解决方法就是判断GTK的版本,如果版本小于2.20,就绘制矩形,否则不绘制。这个方法很恶心,而且天知道新的GTK出来后会不会出问题,至少在文档中没有对gdk_pixmap_new返回的pixmap作任何保证。
后来想到notify-osd在lucid下鼠标穿透的功能依然正常,查看了它的代码,发现对input_shape部分进行了大幅地修改,参考之后代码修改为如下形式:
1 2 3 | GdkRegion *region = gdk_region_new ();gdk_window_input_shape_combine_region (osd->osd_window, region, 0, 0);gdk_region_destroy (region); |
就是创建一个空区域,然后将它作为input shape,因为是空区域,所以整个OSD窗口都是镂空的。
虽然问题解决了,但是还是不明白,为什么之前的方法在GTK 2.20上不能用了(应该说是在GDK 2.20上不能用了),2.20在input shape mask和pixmap上有什么改动,上面的代码要作什么改动才能正常工作呢?如果有朋友知道,请告诉我:)
OSD Lyrics 0.3.20100330
OSD Lyrics 是一个第三方歌词程序,它能为Linux下的多款播放器提供类似Windows下QQ音乐的歌词显示功能,并能自动从网络上下载歌词。
这次的0.3.20100330带来了一项重大更新和几项小更新。
在Emacs中使用gdb调试程序
目录
1 引言
Emacs除了具有强大的编辑功能,还可以作为调试工具gdb的前端,对程序进行调试。使用Emacs进行调试,可以将程序的编写与调试统一到Emacs中,并利用Emacs强大的功能辅助调试,是将Emacs作为IDE使用的一项必备功能。
本文假定读者具有基本的程序调试知识,希望知道在Emacs下进行基本调试的对应操作。水平有限,欢迎拍砖。
2 准备工作:将调试信息编译在程序中
要使程序能被gdb调试,需要在编译时加入调试所需的信息。如果使用gcc/g++进行编译,需要使用参数-g,如:
gcc prog.c -g -o prog
如果使用 ./confiugre && make 的编译流程,可以将使用如下方式引入-g参数:
CFLAGS="-g" ./configure make
注意:不要加入任何优化参数(例如-O、-O2),不然调试时会有很灵异的现象发生……
3 开始:开启Emacs的调试模式GUD
3.1 运行gdb
在编译好程序后,就可以开始调试了。直接运行gdb命令 M-x gdb RET 在minibuffer中会出现需要执行的gdb命令。例如: gdb –annotate=3 prog 如果当前目录下有可执行文件(通常恰好是需要调试的文件),gdb会在其后自动补上可执行文件,否则需要在minibuffer中补上要调试的程序文件名。
继续回车,Emacs的GUD(Grand Unified Debugger)就会关联到gdb并加载要调试的程序了。
3.2 gdb界面
启动gdb后,Emacs的界面会变成下面两种之一:
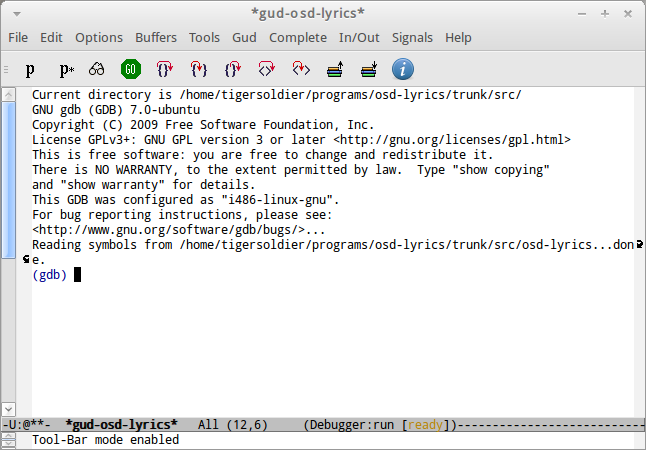
GDB单窗格模式
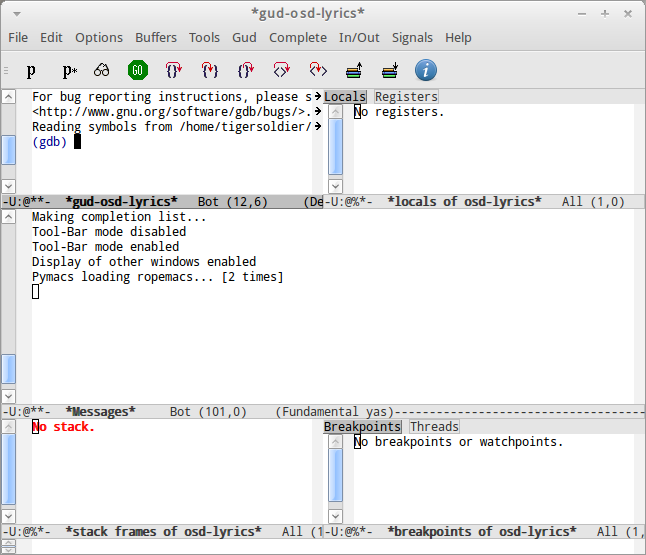
GDB多窗格模式
可以通过gdb-many-windows来切换这两种界面布局。
如果界面被打乱了(例如,在minibuffer中使用补全,查看帮助,重新编译程序),可以使用gdb-restore-windows来恢复界面布局。
3.3 小结
| 命令 | 功能 |
|---|---|
| gdb | 启动gdb进行调试 |
| gdb-many-windows | 切换单窗格/多窗格模式 |
| gdb-restore-windows | 恢复窗格布局 |
接下来就要开始调试程序了。
4 调试:设置断点,控制程序流程
4.1 设置、删除断点
首先将断点设置在要调试的地方。有两种方法:
第一种,在要设置断点的行左边的fringe上单击一下(就是文本左边与滚动条之间空出的那一块)。隐藏了fringe的朋友可以M-x fringe-mode显示它。
第二种,使用默认快捷键C-x C-a C-b, 或者 C-x <SPC>。它们都关联到命令gud-break。
无论使用哪种方法,fringe上都会在设置了断点的行上显示一个红点,表示这行设了断点:

fringe上的断点标记
同时,在断点buffer中也会显示已有的断点信息:

断点buffer
要删除断点,同样有两种对应的方法:在fringe的断点上单击一下,或者使用快捷键C-x C-a C-d(对应命令gud-remove)。
可以在断点buffer上单击某个断点切换到断点所在位置。将光标移动到断点处回车也有同样的效果。
在断点buffer上按空格键可以切换断点的激活和禁用状态。
4.2 运行程序
设置好断点后就可以运行程序了。单击工具栏上的  就开始运行了。也可以使用gud-go命令来运行。奇怪的是没有任何默认快捷键绑定。
就开始运行了。也可以使用gud-go命令来运行。奇怪的是没有任何默认快捷键绑定。
当程序运行到断点时,程序会在断点处停下来,并自动打开停下的语句所在的代码文件。同时在fringe上在停下的语句处有三角形的指示器。

当前语句指示器
现在,我们来一步步运行程序。
4.3 单步执行、运行到光标处
在调试中最常用的功能就是单步执行了。单步执行有两种:将函数调用作为一条语句执行(Next)和遇到函数时进入函数中进行调试(Step)。
要使用第一种方式,默认快捷键是C-x C-a C-n,对应命令为gud-next。也可以单击工具栏上的  。
。
第二种方式的默认快捷键是C-x C-a C-s,对应命令为gud-step。也可以单击工具栏上的  。
。
如果想跳出当前函数,可以使用命令gud-finish,默认快捷键为C-x C-a C-f,工具栏上有  可用。
可用。
在Emacs中还可以运行到光标所在的行。使用命令gud-until即可,默认快捷键为C-x C-a C-u。(注:我在使用时只有光标所在的行在当前行之后并且位于同一函数内才行,否则会跳到很奇怪的地方,还请高手指教)。
也可以直接把当前语句指示器拖到任意一行,程序会运行到那一行再停下来。
4.4 继续运行程序
在程序中断后要继续运行程序,依然是使用gud-go命令或 ,也可以使用命令gud-cont,对应快捷键为C-x C-a C-r。
4.5 小结
| 功能 | 命令 | 默认快捷键 |
|---|---|---|
| 添加断点 | gud-break | C-x C-a C-b 或 C-x <SPC> |
| 删除断点 | gud-remove | C-x C-a C-d |
| 运行/继续程序 | gud-go | 无 |
| 单步执行,无视函数 | gud-next | C-x C-a C-n |
| 单步执行,进入函数 | gud-step | C-x C-a C-s |
| 跳出当前函数 | gud-finish | C-x C-a C-f |
| 运行到光标所在语句 | gud-until | C-x C-a C-u |
| 继续运行程序 | gud-cont | C-x C-a C-r |
5 察看变量的值
调试的过程中免不了要查看变更的值。Emacs提供了方便地功能让我们查看变量的值。
5.1 本地变量buffer
如果打开了gdb-many-windows,在右上角会显示Locals buffer,其中显示了当前局部变量的值。如果显示的是寄存器(Register)buffer,单击左边的Locals就可以切换到Locals buffer了。在其中可以方便地观察到各变量的值。
如果没有打开gdb-many-windows,也可以使用gdb-display-locals-buffer来显示该buffer。
5.2 察看变量值
遇到一些Locals里没有显示的变量,或者比较复杂的结构,就需要用到观察变量的功能了。
将光标停留在要观察的变量上,执行命令gud-watch,可以将变量加入观察列表中。默认的快捷键是C-x C-a C-w。也可以使用工具栏上的  。
。
被观察的变量将在Speedbar中显示。对于复杂结构,可以单击Speedbar上的+号将其展开或收缩。在+号上按空格键也有相同的效果。(注:我在使用过程中经常出现展开没反应,或者加入新元素后才展开,运行几步才展开的情况,求高人讲解)
有时候Emacs观察的变量不是你所想要的,一般是a->b这类的情况。这时可以将要观察的部分选中,再使用上述方法即可。
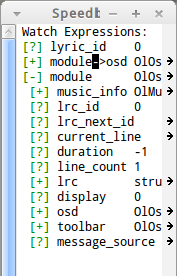
在Speedbar中观察变量
5.3 用工具提示显示变量值
可以用gud-tooltip-mode开启或关闭工具提示。开启后将鼠标指针停留在变量名上时将在工具提示中显示变量的值。

在工具提示中显示变量的值
5.4 小结
| 功能 | 命令 | 默认快捷键 |
|---|---|---|
| 观察变量 | gud-watch | C-x C-a C-w |
| 展开/收缩变量 | <SPC> | |
| 开启/关闭工具提示 | gud-tooltip-mode |
6 输入输出
如果程序需要与标准输入/输出交互,那么你很可能需要用到下面要介绍的功能。
6.1 单独的IO buffer
默认来说,程序的输入输出是在gdb buffer里显示的。这样输出信息和gdb信息混合在一起,阅读起来非常不便。这时候,你需要把输入输出单独显示在一个buffer里,方便查看。
使用gdb-use-separate-io-buffer,可以在程序代码buffer右侧新建一个IO buffer,程序对标准输入输出的操作都会重定向到这里。再执行一次该命令则会隐藏。
6.2 输入数据
需要输入数据的时候,只需要在IO buffer中输入数据回车即可。已经输入的数据会被加粗,以和输出信息区分开来。
6.3 重定向到文件
有时候我们已经准备好了用于输入的数据在文件中,以避免调试时烦琐的输入。这时候就需要在调试时进行输入输出重定向了。
要进行重定向,只能使用gdb自带的功能。在gdb buffer中输入 run < data.in > data.out 就可以将标准输入重定向到data.in,将标准输出重定向到data.out了。
7 按键绑定
说实话,gud自带的按键绑定实在是麻烦,使用一个功能要三次组合键才行,小姆指按Ctrl都按酸了。所以一般将常用的按键绑定在方便的位置,这样才能有和另的IDE一样的快感。
以下是将F5、F7、F8分别绑定到gud-go、gud-step和gud-next的代码:
(add-hook 'gdb-mode-hook '(lambda ()
(define-key c-mode-base-map [(f5)] 'gud-go)
(define-key c-mode-base-map [(f7)] 'gud-step)
(define-key c-mode-base-map [(f8)] 'gud-next)))
之所以绑定到c-mode-base-map上,是因为我基本上在代码buffer中调试。如果要在gdb-buffer中使用的话,需要使用gud-mode-map。如果想在所有buffer上使用的话,可以绑定到全局按键中:
(global-set-key [(f5)] 'gud-go)
8 结尾
有了调试功能,Emacs作为一个IDE才算是完整了。本文介绍了在Emacs下使用gdb调试的基本方法。由于我也是边学边写,一定有许多不足或者错误,还请各位多多指教。
OSD Lyrics 0.3 发布
OSD Lyrics 是一个第三方歌词程序,它能为Linux下的多款播放器提供类似Windows下QQ音乐的歌词显示功能,并能自动从网络上下载歌词。

OSD Lyrics当前支持Amarok、Audacious、Banshee、Exaile、MOC 2.5、 Quod Libet、MPD、Rhythmbox、Songbird、XMMS2,可以从搜狗或千千上下载歌词。
自 OSD Lyrics 0.2 版发布以来,已经过了快半年了。在这半年里,OSD Lyrics 有了不小的进步。在新年到来之际,我认为积累的改动足以把版本号加上0.1了(简单来说,因为过年了,所以版本升级了:))。
OSD Lyrics 添加Quod Libet支持
今天OSD Lyrics添加了第10个播放器支持——Quod Libet。Quod Libet的支持有些不完善的地方,主要是:
- 不支持停止——因为Quod Libet里根本就没这个概念
- 不支持跳转到指定时间——它的dbus接口没有提供这一选项。虽然现在用不到,不过很快就会有功能要用到它了
- 不支持获取播放文件的地址——也就是说,不能根据音乐文件地址来查找歌词了
不过Quod Libet似乎要支持MPRIS,如果支持的版本出来了,那么就可以完美了
使用Emacs daemon
什么是 Emacs daemon
关于Emacs有一个很著名的笑话,就是Emacs = Emacs Makes A Computer Slow。Emacs启用慢是一个人尽皆知的事实。由于启动时要加载大量的脚本和插件,使得Emacs在启动时往往需要数秒之久。因此我在进行一些快速简单的任务,如svn commit时,都是使用nano或者vim来进行的。
Emacs daemon就是为了这个而诞生的。它将Emacs变成了一个C/S模型——只需要启动一个服务器在后台作为守护进程(daemon)跑着,之后启动的每个emacs都是一个客户端,它连接上服务器进行工作。这样一来,只要在启动服务器时运行初始化脚本,客户端启动无需运行脚本,实现启动时间从Firefox到Chrome的转变。
使用 Emacs daemon
要使用Emacs daemon,至少需要Emacs 23。它提供了一个emacsclient程序,用于启动客户端。
有客户端就必然要有服务端。要启动一个daemon,需要在运行emacs时加入一个--daemon参数。幸运的是,我们不用手动启动服务端,而是可以利用emacsclient的-a参数。emacsclient的-a参数用于指定连接不上服务器时使用的别的编辑器(alternate editor),当把这项留空时,它会自动启动服务端。如果不想指定-a,也可以将ALTERNATE_EDITOR环境变量设为""。
除了-a参数,emacsclient还要手工指定使用终端还是X来启动。要从终端启动,需要使用-t参数:
1 | emacsclient -t -a "" |
从X启动则是-c:
1 | emacsclient -c -a "" |
方便些,再方便些
每次都要输入上面那些命令太烦了,不符合*nix的终极目标——偷懒
首先把终端版本设一个alias。编辑~/.bashrc,在最后加入
1 2 3 4 | #用ec来快速启动emacs clientalias ec='emacsclient -t -a ""'#现在可以将emacs设为默认编辑器啦:Pexport EDITOR="ec" |
以后在终端下输入ec就可以启动emacs的终端客户端了:)
在X下,我习惯用gnome-do来启动程序。因此最方便的方法就是建立一个菜单项,名叫Fastmacs,内容自然就是X模式启动emacsclient的命令啦
配置,还是配置
俗说说得好,.emacs说有多少就有多少+1。如果在.emacs里对X相关的选项(字体什么的)直接进行设置,那么会发现用emacsclient启动时,这些设置都失效了。这是因为这些设置是在X下的frame创建时才有效的,而启动服务器的时候是没有创建frame的。
解决方法有两种,一种是使用after-make-frame-functions这个hook,在创建一个frame之后才进行设置。代码如下
1 2 3 4 5 6 7 8 9 10 11 | (defun frame-setting () (set-frame-font "文泉驿等宽微米黑 8") (set-fontset-font "fontset-default" 'gb18030 '("文泉驿等宽微米黑" . "unicode-bmp")))(if (and (fboundp 'daemonp) (daemonp)) (add-hook 'after-make-frame-functions (lambda (frame) (with-selected-frame frame (frame-setting)))) (frame-setting)) |
需要判断是否以daemon模式启动,分别进行处理
另一种方法是设置window-system-default-frame-alist,直接设置参数的默认值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | (setq window-system-default-frame-alist '( ;; if frame created on x display (x (menu-bar-lines . 1) (tool-bar-lines . nil) ;; mouse (mouse-wheel-mode . 1) (mouse-wheel-follow-mouse . t) (mouse-avoidance-mode . 'exile) ;; face (font . "文泉驿等宽微米黑 8") ) ;; if on term (nil (menu-bar-lines . 0) (tool-bar-lines . 0) ;; (background-color . "black") ;; (foreground-color . "white") ) ) ) |
可以设置的参数见Emacs Lisp Reference > Frames > Frame Parameters
推荐使用第二种方法,启动客户端时直接就使用所设置的字体了
参考文章
http://www.wanglianghome.org/blog/2009/01/customization-tips-for-emacs-daemon.html
http://jackycxh.blog.35.cn/2009/07/22/emacs-daemon-and-font/
将CNNIC证书清出Chromium for Linux
update:发现还需要禁用entrust的证书,但是entrust被内建在chromium里了,有什么办法能禁用它呢……
这就是所谓的“老鼠过街,人人喊打”吧。
废话少说,进入正题。由于Chromium在Linux上使用的是系统的证书,所以要使用系统自带的工具来清除。
具体方法参考自http://code.google.com/p/chromium/wiki/LinuxCertManagement
安装工具
Ubuntu/Debian:
1 | sudo apt-get install libnss3-tools |
Fedora:
1 | su -c "yum install nss-tools" |
Gentoo:
1 | su -c "echo 'dev-libs/nss utils' >> /etc/portage/package.use && emerge dev-libs/nss" |
Opensuse:
1 | sudo zypper install mozilla-nss-tools |
列出证书
1 | certutil -d sql:$HOME/.pki/nssdb -L |
在我机子上结果如下:
Certificate Nickname Trust Attributes
SSL,S/MIME,JAR/XPI
…………………………
Starfield Secure Certification Authority #2 ,,
CNNIC SSL ,,
VeriSign, Inc. ,,
……………………
删除证书
将CNNIC赶出系统:
1 | certutil -d sql:$HOME/.pki/nssdb -D -n "CNNIC SSL" |
完成后再列出证书,可以发现没有CNNIC的身影了。
重启Chromium,登录CNNIC认证的一个网站:www.enum.cn/en/,是不是已经不受信任了?
一些补充
- 在Gentoo下,要将certutil命令改为nsscertutil
- 此方法只是删除CNNIC证书,目前我并不清楚它会不会又回到系统中。如果有将其彻底屏蔽的方法,请告诉我
OSD Lyrics 0.2.20100201
忙了一个多星期,终于把这个版本给弄出来了
没有什么新功能增加,只是修复了一个严重的bug:下载歌词时,如果网络不好导致DNS超时,OSD Lyrics 100%会崩溃。
Bug原因很清楚,也很严重,之所以拖了那么久才解决,是因为修复这个bug要伤筋动骨一番。最后把歌词下载模块改成了多进程方式,这回应该可以根除它了。
另外根据zuolun同学的建议,提供文字轮廓宽度调节选项。
回归多进程下载模型
在用多进程下载模型可耻地失败之后,OSD Lyrics使用了多线程模型来对歌词进行下载。在完成之后发现每当DNS超时时,程序都会崩溃。经过不断地调试,确定是curl的问题。看了文档后发现,原来curl在多线程环境下,由于DNS查找超时是使用信号实现的,所以在多线程环境下是不安全的。当时想了两个方法:在自己的程序里包含curl,启用异步DNS查询cares;或者大幅修改程序,使用curl的异步查询接口重写下载引擎,把程序重新变成一个单进程、单进程的程序。第一种方法会让代码的大小和编译时间大幅增长,第二种方法要把两个下载引擎(搜狗和千千的)给大幅改写,过于复杂。于是一直纠结……
后来请教了 @henry_ 老师,一句话把我打回原点——用多进程才是王道。
进程vs线程
重新审视自己的设计和多进程模型失败的原因:因为在子进程中使用了X的操作。为什么会有X的操作呢?看看下载一个歌词的步骤:
- 搜索歌词,并将搜索结果返回
- 如果有多个搜索结果,弹出选择窗口
- 下载选中的歌词
- 下载成功,显示歌词
之所以会有X操作,是因为第2步弹出了一个窗口。由于子线程同样不能操作GUI元素,因此多线程模型同样要在主线程中处理弹出窗口。我在设计中将下载过程给模块化了,有一个专门的下载模块,将具体的下载引擎和主程序分开。线程化后的下载过程是这样的:
- 主程序向下载模块注册搜索和下载回调函数
- 主程序发起搜索请求
- 下载模块建立搜索线程,搜索线程调用下载引擎的搜索函数,返回后唤醒下载模块在主线程的回调函数
- 下载模块的回调函数调用所有注册了的搜索回调函数
- 主程序的搜索回调函数弹出选择窗口
- 下载模块建立下载线程,下载线程调用下载引擎的下载函数,返回后唤醒下载模块在主线程的回调函数
- 下载模块的回调函数调用所有注册了的下载回调函数
- 主线程的下载回调函数显示歌词
也就是说,只是将原来的第1步和第3步线程化了,而这两步是没有X操作的。而且由于将下载过程都放在下载模块里了,因此多线程部分完全是在下载模块里实现的,主程序和下载引擎一点也不知道多线程的存在。
既然如此,为何不讲它们进程化呢?把实现中的线程改成进程,就是多进程模型了。一旦这样做的话:
- 子进程中没有X操作
- 只需要修改下载模块,主程序和下载引擎不需要修改,工作量小,不易出错
- 多进程不会再有信号的问题。更进一步来说,子进程你爱挂就挂吧,对父进程半点影响都没有,多健壮啊
- 进程之间没有公共数据,无需同步,不怕数据修改
- 我管你子进程怎么分配内存,反正一退出全回收了
- ……………………
明白自己要什么
首先搞清楚自己需要怎样的多进程操作:
- Unix的
fork风格 - 异步函数调用形式,在fork时指定回调函数,子进程退出后自动调用回调函数
- 子进程能返回数据到回调函数中,不只是退出状态
简单来说,就是要一个刚好能替代现有线程操作的方案,而且它是和现在的线程操作类似的,这样使用起来直观,而且修改难度小。
然而我遇到了一个问题。
如何从子进程中返回数据
从子进程中返回数据的问题思考了很久,因为进程间通信不像线程间通信那么简单,直接传一个指针完事。@henry_ 老师给我指明了两条路:使用管道或共享内存。
就此思考了一番。管道需要将返回数据序列化,再通过管道传送,最后反序列化还原数据。共享内存不需要序列化,但是需要自己管理内存,而且不知道要开多大的共享内存,内存的分配与释放都要仔细考虑。
最后的决定是使用管道。虽然要实现序列化操作,但是过程简单清晰。如果使用共享内存,那么设计会变得很复杂,容易出错,而且内存相互分离的优点也没了。
具体设计
把一切都想清楚之后设计就很清晰了。
- fork前打开管道
- fork时指定回调函数
- 子进程使用管道写入数据,然后退出
- 父进程从管道读入数据,然后调用回调函数并将数据传入
- fork模块只负责传递数据,不负责序列化操作
最后的设计只有一个函数:
1 | pid_t ol_fork (OlForkCallback callback, void *userdata); |
回调函数的定义如下:
1 2 3 4 | typedef void (*OlForkCallback) (void *ret_data, size_t ret_size, int status, void *userdata); |
同时,为子进程提供了用于返回数据的文件描述符和文件流:
1 2 | extern int ret_fd;extern FILE *fret; |
实现细节
剩下的最大问题就是如何在子进程退出时调用回调函数了。最直接的想法就是处理SIGCHLD信号。由于不同的子进程可能需要调用不同的回调函数,也有不同的用户数据,因此需要有一个子进程ID和回调函数的对应表。感谢GTK、GDK、GLib,现在只需要用g_child_watch_add就一切都搞定了。
关于序列化,本来是想用protobuf的,它的C绑定似乎还直接提供了RPC的支持。由于我只是简单的需要一个IPC的数据传递,干脆自己写一个来练手好了。
序列化的协议很简单。因为只有两种结构需要序列化——数组和结构体,所以就简单地定义了一下。对于结构体,将其字段按一定顺序输出,以换行符间隔。对于数组,先输出一行总数,再输出各元素,每个元素后再加上一个换行符。由于是程序内部用的IPC数据,因此只要单元测试通过了,数据的正确性就可以完全信赖,不需要复杂的容错机制。
一些弯路
一开始在考虑子进程返回的触发时,@henry_ 提示可以用select或者poll。实现了之后发现有两个问题,一是如果子进程的返回数据是分段输出的话,回调函数可能会调用几次,每次收到一段数据;二是如果子进程没有返回数据(也就是返回数据为空),那么回调函数根本就不会运行。因此还是老老实实采用子进程退出来触发回调函数。
开始的设计是向回调函数传递一个fd,让回调函数自己读取数据。这么做是为了能让回调函数利用fgets来读取一行。思考之后觉得这样很不自然,而且回调函数要考虑的东西反而多了,复杂了,于是改成了现在这个样子。
在实现序列化的时候没有想清楚,把不需要序列化的OlMusicInfo给序列化了,白做工了。
在反序列化结构时,一开始是返回true or false,后来发现一个问题,就是在反序列化数组时,不知道一个元素反序列化后,剩下未被反序列化的数据从哪开始。于是把接口改成了返回指向剩下数据开头的指针,如果失败就返回NULL。
结论
把fork模块和序列化做好之后,修改代码就很简单了,只需要把对应的地方改一下,程序很欢快地跑了起来。
使用多进程的设计,避免了修改curl使用方式的缺点,而且使得程序更健壮。由于Linux轻量级进程的优势,多进程和多线程的性能应该没有太大的差别,而且实际上下载也不是程序的瓶颈。
此次设计进行了仔细考虑,而没有像之前边做边迭代的方法。在明确自己的目标,排除多余的东西,对各方面作出权衡和折衷之后,得到了一个比较简洁的接口和实现,自己觉得还是很满意的。
实现的过程中对新的代码做了充足的单元测试,发现了一些问题,同时修正了设计,最后用起来自己也相当放心。在代码不是立刻可以整合到系统中的时候,单元测试往往是能立刻看到成果的方式,而且也能检验自己的设计是否合理。
从多进程到多线程,最后又回到多进程,貌似绕了个大弯又回到原点。但是这两个多进程的设计高度完全不一样。在实现了多线程机制后,对整个下载的过程和实现有了充分的了解,现在的多进程流程也是在多线程的设计中定下的。如果没有多线程模型这个探索,也就很难有现在这个设计。所谓螺旋式上升嘛,说不定以后又会改成多线程,但是可以肯定的一点是,一定会比现在的要更好。

![tigersoldi[at]gmail[dot]com](http://tigersoldier.is-programmer.com/user_files/tigersoldier/Image/gmail.png)